
The cloud ecosystem has reached a turning point. Tools for operators/administrators are now mature and can handle most day-to-day operations that deal with Kubernetes clusters. Finally, we can turn our focus to application developers and their needs.
If you look at all the Kubernetes tools available, you’ll understand that most of them treat Kubernetes as another form of infrastructure. You can easily find tools that install Kubernetes, monitor Kubernetes, secure Kubernetes, do cost estimations for Kubernetes, etc. But how many Kubernetes tools can you find that target application developers and their day-to-day responsibilities?
Several companies even try to hide Kubernetes completely from developers by using leaky abstractions or so-called developer portals. These adoption efforts almost always fail simply because nobody asked the developers what they really need. Don’t fall into this trap.
In this article, we see some common examples of what companies “think” about developers’ needs versus what developers need in practice, in the context of application development for Kubernetes.
Confusing clusters with environments
When designing a deployment workflow, most teams center the discussion around individual clusters. You often hear people talk about direct mappings between clusters and “environments”.
- “This is our production cluster.”
- “Our staging cluster is down.”
- “We need a new cluster for QA.”
This forces all Kubernetes tools to expose clusters as first-level constructs in their user interface (UI). If your team has created any kind of dashboard for Kubernetes, I can bet that the left-panel navigation contains a “cluster” entry where people can look at individual clusters.
In reality, developers never care about individual clusters. Most times, they care about:
- Cluster groups that behave the same (e.g., prod-us, prod-asia, prod-eu).
- A set of namespaces within a big cluster (most common in shared qa/staging clusters).
- A combination of the above.
Developers have a different mindset:
- “I am ready to ship this feature to production.”
- “Oh, my new feature is failing in the QA environment.”
- “That is strange, application 1.23 works ok in QA, but presents an error in the staging environment.”
So, how many clusters are in production, QA, or staging? It does NOT matter to developers. Folks only think that developers care about environment settings and, more specifically, what differs between environment configurations.
This means that if your internal portal/developer platform looks like this:
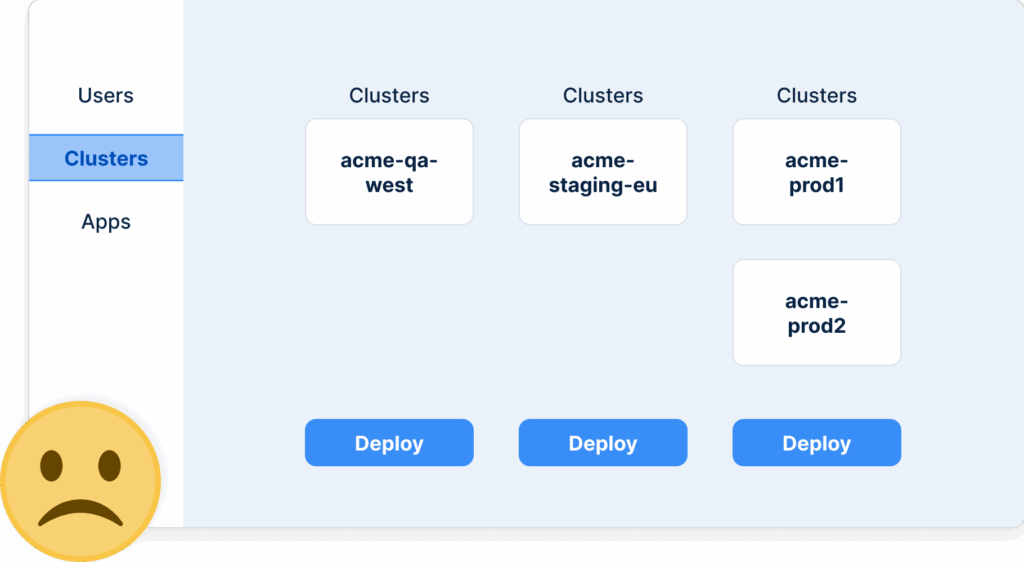
You need to redesign it like this:

Let me repeat that again. Developers do NOT care about individual Kubernetes clusters. They mostly care about the different settings between the cluster groups that represent each “environment”.
Promotions are more important than deployments
We’ve established that developers prefer thinking about environments and not individual clusters. Let’s see another common misconception with tools that target developers. If you look at the most typical scenario of how a feature reaches production, this is the process:
- A developer performs an initial deployment in the first environment—let’s call it QA environment.
- After passing several tests and reviews, the feature gets promoted to the staging environment.
- After passing several tests, the feature gets promoted to production.
- Depending on the company, there might be several other intermediate environments where promotions happen (e.g., load testing).
Several tools promise to simplify deployments for Kubernetes developers. It turns out that developers are actually interested in promotions. There are 3 main reasons for that:
- A deployment (where code is packaged in a brand new artifact) happens only once in the first environment. In all the subsequent environments, developers want to promote an existing image/configuration/release/artifact and not deploy anything from scratch
- Problems with promotions have more impact. Promoting to production is always a risky process. Deploying to QA is not.
- Promotions can often fail due to external configuration not directly controlled by developers.
The last point cannot be overstated. One of the most common cases for failed deployments in production is the difference in environment configuration. Developers dutifully tested their application in QA and staging, and everything worked fine. Then the application failed to deploy in production because of an unexpected change in production settings completely outside the scope of the application container.
Continuing our wireframe from an imaginary developer portal, most teams think that developers need this:

The UI is problematic for many reasons:
- Developers can deploy an older version to any environment by mistake.
- Developers need to manually correlate versions between environments and understand what was in the next/previous environment.
- Most times, versions correspond to Docker image versions that exclude external configuration.
But as explained already, developers just want to promote. So they would prefer this:

Notice that this makes a developer’s job very easy. There are also several guardrails in place. At a minimum, the production drop-down can ONLY promote what is currently in staging and nothing else (or maybe the last 3 versions that are available in staging). You can also perform checks and present warnings in several scenarios (for example, if a developer tries to promote something to production that is clearly failing in staging).
Developers don’t care about Git hashes
Git hashes are great when it comes to source code operations. When developers perform basic merges, cherry-picks, and rebase scenarios, they do care about Git hashes. But when it comes to deployments, Git hashes mean nothing:
- Git hash names have no specific order. You cannot look at 2 hashes and understand which is newer/older.
- Git hashes can only capture the state of a source code snapshot or the specific commit for Kubernetes manifests, but never both at the same time.
- They allow for mistakes when it comes to deployments, especially when developers have to copy/paste hashes between different tools.
What developers care about instead is software versions. Version numbers are simple to read, simple to reason, and simple to understand.
Products and dashboards that expose Git hashes as a central concept are cumbersome and difficult to use. It’s ok if Git hashes are an additional piece of information for a deployment, but they should never be used for direct promotions or other day-to-day operations.

What developers really want to see are versions. Or, at least some kind of numbering where ordering is easy to understand.

So, where do these versions come from?
Here we reach one of the biggest misconceptions about container images for Kubernetes. Several tools (and dashboards) simply use a special tag with a version number on a container that gets “promoted” from each environment to the next. Using a container image version for the promotion process might make sense at first glance.
However, this approach misses 2 facts completely:
- Docker tags are mutable by default. Just because you see a container called my-image:v1.0 in one environment and another container my-image:v1.0 in another environment, that doesn’t mean they’re the same application. They might be completely different.
- Used as an application version, the container tag only works in 80% of cases. Developers sometimes need to promote a container image AND associated configuration (like configmaps and secrets). In those cases, the container tag is NOT enough to understand what gets promoted and where.
You can partially solve the first problem with tooling support. You need to instruct ALL tools that take part in the software lifecycle to treat container tags as immutable. This is also a very basic requirement for any package registry that your organization is using.
You can solve the second problem with Helm charts. Helm charts give you access to 2 additional “version” properties (in addition to your container tag). You can annotate a Helm chart with an “application” version and also have a different version for the chart itself. This way, when you promote a Helm chart, you can promote a container image PLUS additional configuration in a single step.
However, not all organizations use Helm charts. Several teams prefer to use Kustomize or even plain manifests. In this case, the versioning problem still exists.
Unfortunately, most tools assume that developers only care about container images and center their whole interface around image tags.

Developers would prefer a system that lets them promote configuration and container tags at the same time. This would cover 100% of their needs and cater even to edge case scenarios where they only promote configuration, while the container image stays the same.

Tools that expose Git hashes and assume developers only work with container tags completely miss the way Kubernetes applications work.
Don’t abuse pipelines as promotion mechanisms
Many developers see Continuous Delivery (CD) as the next evolution of Continuous Integration (CI). After all, before you deploy a container image, you need to build and test it first.
Several teams that switch to cloud-native development make their first step in CD by abusing their existing CI pipelines. Developers love to see a single pipeline that shows the whole picture for a specific feature, from the initial code commit all the way through to production.
The main problem here is that the typical CI pipeline only knows what is happening WHILE it’s running. After it finishes, it has no visibility into the actual cluster.

This leads to the classic problem of failed deployments in the following manner:
- A developer commits a new feature (or merges something in a branch).
- The CI pipeline starts and then builds/tests a container image with success.
- The CI pipeline deploys the image to a Kubernetes cluster and optionally runs some checks.
- Everything looks good, and the pipeline shows its status as “green”.
- Ten minutes later, the application has issues (memory leaks, wrong dependencies, missing DB).
- Developers get paged about a failed deployment, even though the pipeline STILL shows as green.
Your organization probably falls into this trap if developer teams always talk about “lack of deployment visibility”, “wasting time to troubleshoot deployments”, “not enough production access”, and similar complaints.
In reality, developers look at the CI system for the basic build. Then they need to go to another system (usually a metrics/monitoring solution) to understand what’s happening with their application.
The key takeaway here is that instead of a basic CI pipeline, you need a system that gives developers real-time information about deployments and promotions. In that system, the “green” status means that the application is healthy RIGHT NOW, not 5 minutes before.

Now developers can use a single interface for deploying/promoting, and understanding if the application is healthy. They can go to their metrics solution when things go wrong, but in the happy path scenario, a single system can tell them if the application is successfully running in a Kubernetes cluster (or a specific environment, as we saw earlier in the article).
Stop deploying and start promoting
You should now understand what developers actually need and why existing solutions aren’t designed with Kubernetes/GitOps in mind. There are several initiatives right now for investing in developer portals in big organizations, and, unfortunately, developers don’t always have a say about exactly what they need from an internal platform.
The next question is whether you actually need to create a platform like this from scratch. You might think that Argo CD is a solution that helps developers with Kubernetes deployments and that simply adopting Argo CD will make developers happy. In reality, Argo CD is a great sync engine, but doesn’t try to solve changes between applications, promotions, or environments. For example, Argo CD doesn’t have the concept of environments, instead only operating with individual clusters.
This is why we extended Argo CD to create Codefresh GitOps Cloud. We looked at existing solutions and understood that developer experience is always an afterthought, even in newer platforms that are supposedly designed with Kubernetes in mind.
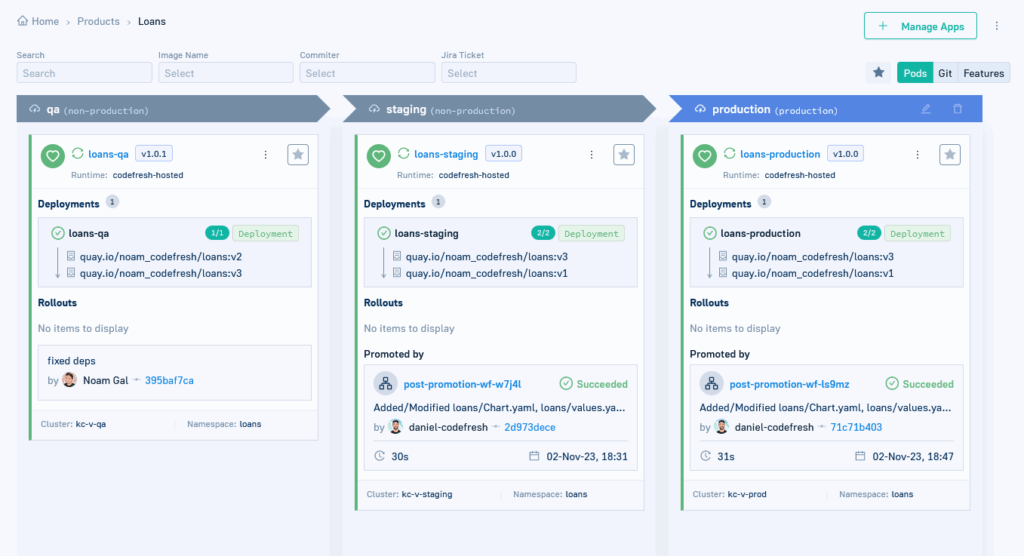
Codefresh GitOps Cloud implements all the best patterns we explained that developers need:
- It works with environments instead of individual clusters. Each environment can be one cluster, a set of clusters, a set of namespaces, application labels, or any combination of those.
- It’s based around promotions. Developers can easily understand what’s different between 2 environments and how to move an application from one environment to the next.
- Git hashes are there if you need them. The central construct, however, is products and their versions. A product is a new entity that includes an application along with its configuration and its container images. When you promote from one environment to another, you promote the whole application and not individual container images.
- The graphical dashboard always shows real-time information. When you see a “green” checkmark, it means that an application is running successfully in an environment right now. Developers can detect right away what deployment was successful and what failed without going to another system.
- Argo CD and its amazing sync engine power everything behind the scenes.
You can use Codefresh GitOps Cloud today along with your existing CI system (like Jenkins and GitHub Actions). GitOps Cloud doesn’t replace your CI solution. It makes developers happy by giving them a dedicated platform for application promotions, which is what developers really need (instead of playing deployments).
Oh, one more thing. If you already have your own Argo CD instance, you can bring it along!
Ready to start your GitOps journey with Codefresh? Try GitOps Cloud free for 45 days now.